Database API

This chapter provides information that enables programmers to build applications that make use of Source-Navigator's project databases. It covers the API, including available functions and their syntax.
This chapter assumes that you are familiar with the Tcl or C programming languages. For information about Tcl see Practical Programming in Tcl and Tk1 and Tcl and the Tk Toolkit2, and for information about C refer to The C Programming Language3.
Source-Navigator project information is stored in a database . There is one database for each project and the database may contain one or more views. A view is a named subset of records; this might be the subset of all .h files, or the subset of all files in a given subdirectory. Views are a powerful and fast way to narrow down a large project without building multiple projects (see Views).
A database consists of 15 to 25 files; each file consists of a table that contains symbol and index information. Database files are regular files in the operating system and can be shared between UNIX and Windows operating systems.
When you create a project with Source-Navigator, a database is created under the projectdir /SNDB4 directory. By default, this location can be changed in the Project Preferences dialog when the project is created. See General Project Preferences of User's Guide for more information. Each database file is created with a filename starting with projectname , where projectname is the project name you chose and projectdir is the project directory you chose. One or more databases may exist under the same directory.
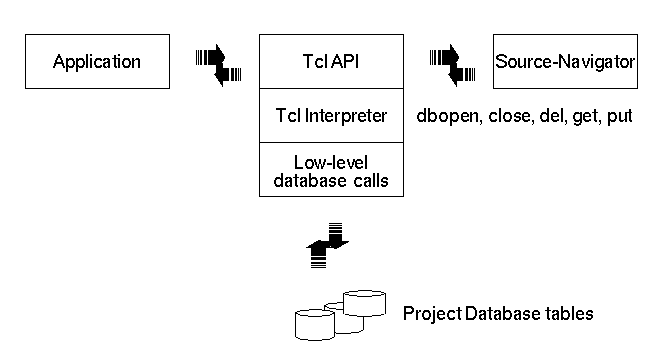
Each file is a table that contains specific symbol information and indexes. A database table can be accessed via an index, which is handled internally by the database, or sequentially. To use the Tcl API, you do not need additional header files, compilers, or libraries. All of the Tcl commands you need to work with a Source-Navigator project database are built into the Source-Navigator Tcl interpreter called hyper.
In previous versions of Source-Navigator, fields in the database were separated by space characters. To accommodate filenames that contain spaces, the field separator has been changed to an internal value that can be referenced through the read-only Tcl variable sn_sep. See the scripts under Cross-Reference Tables for more information on this variable.
The first three lines of the scripts in this chapter are "boilerplate" text to run these scripts under UNIX. On Windows you must delete these lines and run the remainder from a file using SNsdk.
To run standalone Tcl scripts (see multicludes.tcl) under Windows NT, an execution command must be used. The usage of this command is:
SNsdk <script name> <arguments>
To run the multicludes.tcl example script on a project called test1 in the C:\test directory the syntax would be:
SNsdk multicludes.tcl C:\test test1
The database may be accessed by a set of Tcl commands. The primary goals in designing the API were performance and flexibility; for high-level queries, the Tcl language provides a powerful and flexible solution.
The database supports the btree and hash file formats. The btree format is a representation of a sorted, balanced tree structure. The hash format is an extensible, dynamic hashing scheme.
The dbopen, close, del, get, put, and seq routines are used to access the database. Optimal database tuning calls and parameters may also be configured in Tcl using the cachesize and pagesize properties (see dbopen) to give optimum performance in specific applications.
Views define sets of files to include or exclude from queries. The hidden files list is stored in a view. For example, in a project where you have both database- and GUI-specific source files, you can hide the database file sql.c and save the remaining project information as a view. Hiding this view means the records with references to the file sql.c must be skipped. The following example lists a view table:
set db_view [dbopen nav_view SNDB4/cpl.2 RDONLY 0644 hash \ cachesize=300000] puts stdout [join [ $db_view seq -data] \n]
sql.c
Views have to be specified when a table is opened using the dbopen command; the application does not have to be changed.
The example below uses a view. The view table in the following example (SNDB4/cpl.2) is created using the Editor. The first view in a project has the suffix .1, the second .2. There is no limit for views.
#!/bin/sh
# Replace $HOME/snavigator with the Source-Navigator
# installation directory! \
exec $HOME/snavigator/bin/hyper "$0" "$@"
#
# Don't forget the backslash before exec!
#
set db_view [dbopen nav_view SNDB4/cpl.2 RDONLY 0644 \
hash cachesize=300000]
set db_functions [dbopen nav_func SNDB4/cpl.fu RDONLY \
0644 btree cachesize=20000 $db_view]
# Output the list of matches with newline characters
# after each.
puts [join [$db_functions seq -data] \n]
# Force our way out of this event-driven shell.
exit
Source-Navigator stores the cross-reference information in two tables with the suffixes by and to. They contain the same information, only their key format differs. The to table keeps the Refers-to information and the by table the Referred-by information. The following script opens the to cross-reference table of a project and lists its contents.
#!/bin/sh
# Replace $HOME/snavigator with the Source-Navigator
# installation directory! \
exec $HOME/snavigator/bin/hyper "$0" "$@"
#
# Don't forget the backslash before exec!
#
set db_functions [dbopen nav_func .sn/cpl.to RDONLY 0644 btree \
{cachesize=200000}]
puts [join [$db_functions seq -data] \n]
exit
The above script would generate these results:
# len fu # strlen fu p 000019 c.c # main fu # glob_var gv w 000010 c.c # main fu # len fu p 000013 c.c # main fu # printf fu p 000013 c.c # main fu # strcpy fu p 000012 c.c
The hash (#) characters mean that the symbols do not belong to any classes. To fetch only the references in the main function, modify the fetch instruction:
$db_functions seq -data [append "#" $sn_sep "main" $sn_sep]
In the query, note that the first character of the key must be a hash (#) character because main is not a method but a function. To be sure that only the references of main are reported, a separator character ($sn_sep) has to be added to the string main. Without the separator, the query would report the references of all functions whose names begin with the string main.
An example of the result after the modification:
# main fu # glob_var gv w 000010 c.c # main fu # len fu p 000013 c.c # main fu # printf fu p 000013 c.c # main fu # strcpy fu p 000012 c.c
If an application collects references to a function Referred-by, it is better to use the by database table.
The script below opens the Referred-by table and reports every reference to the global variable glob_var and the function len.
#!/bin/sh
# Replace $HOME/snavigator with the Source-Navigator
# installation directory! \
exec $HOME/snavigator/bin/hyper "$0" "$@"
#
# Don't forget the backslash before exec!
#
global sn_sep
set db_functions [dbopen nav_func SNDB4/cpl.by RDONLY \
0644 btree cachesize=200000]
# Output the cross-references which match the following
# criteria, with newline characters between all of them.
puts [join $db_functions seq -data \
[append "#" $sn_sep "glob_var" $sn_sep gv] \n]
puts [join $db_functions seq -data \
[append "#" $sn_sep "len" $sn_sep fu] \n]
# Force our way out of this event-driven shell.
exit
# glob_var gv # main fu w 000010 c.c # len fu # main fu p 000013 c.c
The output above indicates that the symbols glob_var and len are only used by the function main.
The Source-Navigator database tables can be accessed by means of Tcl commands created using the dbopen command. The database API can access Source-Navigator tables regardless of whether Source-Navigator is running, or a project is using the target tables.
The dbopen command opens a table for reading and/or writing. dbopen creates a new Tcl object (command) with the name dbobject.
dbopen dbobject tableName access permission type ?openinfo?
|
The desired name of the new command. dbopen will fail if there is already a command named dbobject. |
|
|
The dbopen command opens a table for reading and/or writing. Files not intended for permanent storage on disk can be created by setting the tableName parameter to NULL. |
|
|
The access argument is as specified for the Tcl open routine; however, only the CREAT, EXCL, RDONLY, RDWR, and TRUNC flags are significant. Refer to the Tcl documentation for further information on modes for opening files. |
|
|
If a new file is created as part of the process of opening it, permission (an integer) sets the permissions for the file. On UNIX, this is done in conjunction with the process' file mode creation mask. |
|
|
The type argument must be either btree or hash. The btree format represents a sorted, balanced tree structure. The hash format is an extensible, dynamic hashing scheme. |
|
|
The openinfo optional argument must be a valid Tcl list and can be used to set type-specific properties of database tables. The syntax is as follows: property1=value,property2=value,...\ propertyn=value See Hash Table Properties and Btree Table Properties for valid values for this parameter. |
If the file already exists (and the TRUNC flag is not specified), the values specified for the parameter flags, lorder, and psize are ignored in favor of the values used when the tree was created.
Forward sequential scans of a tree are from the least key to the greatest.
Space freed up by deleting key/data pairs from the tree is never reclaimed, although it is normally made available for reuse. This means that the btree storage structure is grow-only. The only solution is to avoid excessive deletions, or to create a fresh tree periodically from a scan of an existing one (see dbcp).
The instruction below opens (for read-only) a btree database table using cachesize of 2 MB.
set db [dbopen nav_classes brow.cl RDONLY 0644 btree \
{cachesize=2000000}]
The next example opens a hash table that is used later as a view.
set db_view [dbopen nav_view SNDB4/progs.1 RDONLY \
0644 hash "cachesize=300000"]
set db_functions [dbopen nav_func SNDB4/progs.fu \
RDONLY 0644 btree "cachesize=200000" $db_view]
With commands created by dbopen, these methods can be used: close, del, exclude, get, isempty, put, reopen, seq, and sync. In the following examples, dbobject represents the command returned from dbopen.
dbobject close
This method flushes any cached information to disk, frees any allocated resources, and closes the underlying table. Since key/data pairs may be cached in memory, a database should be closed or synchronized before the application exits; this flushes the cache to disk. Failure to close or synchronize can cause data loss. As a final step, dbobject is also destroyed.
dboject
del ?-glob pattern? ?-beg pattern? ?-end pattern?
?-regexp pattern? ?-strstr pattern? ?key? ?flags?
This method removes key/data pairs from the table.
With glob, beg, end, regexp, and strstr switches (applicable only to the btree tables), a pattern must be specified to delete every record whose key matches the pattern. If key is specified, only those records are checked for deletion whose keys begin with key.
The parameter flags may be set to the value R_CURSOR. Delete the record referenced by the cursor. The cursor must have previously been initialized.
This method returns the number of the deleted records.
dbobject exclude view
This method effectively sets the view of dbobject by excluding all symbols not in the view. View must be the name of an already existing object created using an earlier dbopen command.
dbobject get key
If key is found, this method returns key and the associated data in separate Tcl lists; otherwise, it returns an empty string. For more information, see Fetching Tables.
dbobject isempty
This method returns 1 if the table (with its current view) is empty, otherwise 0.
dbobject put key data ?flags?
This method stores key/data pairs in the table.
The parameter flags may be set to one of these values:
The default behavior of the put routines is to enter the new key/data pair, replacing any previously existing key.
This method returns 0 on success, and 1 if the R_NOOVERWRITE flag was set and the key already exists in the table.
dbobject reopen
This method closes and reopens the table. This flushes data to disk and resets any views.
dbobject seq option
See Fetching Tables.
dbobject sync
If the table is in memory only, this method has no effect and will always succeed. This method returns 0 on success.
Database tables can be fetched by the get and seq methods.
get returns only one record if the fully qualified key can be found. For more information, see the description of the get method above.
seq can be used to fetch tables sequentially. If the key argument is not given, the whole table is fetched (records to be retrieved can be filtered with patterns). key limits the records that should be fetched. seq may begin at any time, and the position of the cursor is not affected by calls to the del, get, put, or sync methods. Use the optional filters -end, -glob, -nocase, -regexp, -result_filter, and -strstr to limit the retrieved records.
Using key assures the best performance because it already limits the records that should be fetched while the filters limit the results only after the records have been fetched.
By fetching, the view (if any) assigned to the table while it was open is always processed.
Database tables can be fetched sequentially using seq or with indexed get access.
dbobject seq ?-columns column_list? ?-data? ?-end pattern?
?-first? ?-format format_string? ?-glob pattern? ?-key?
?-nocase pattern? ?-regexp expression?
?-result_filter pattern? ?-strstr pattern? ?-uniq? ?-list?
?key? ?flags?
This section provides the equivalent of manual pages for the C Programming API functions.
You must #include <db.h> when using the C API, and you need to link the final executable with libdb.a and libtcl8.1.a to locate the database library routines.
#include <db.h> DB *dbopen(const char *file, int flags, int mode, DBTYPE type, const void *openinfo);
dbopen is the library interface to database files.
dbopen opens file for reading and/or writing. Files that are never intended to be preserved on disk may be created by setting the file parameter to NULL.
The flags and mode arguments are as specified to the open(2) routine; however, only the O_CREAT, O_EXCL, O_EXLOCK, O_NONBLOCK, O_RDONLY, O_RDWR, O_SHLOCK, and O_TRUNC flags are meaningful. (Note that opening a database file O_WRONLY is meaningless.)
The type argument is of type DBTYPE, defined in the <db.h> include file. It may be set to DB_BTREE or DB_HASH.
The openinfo argument is a pointer to an access method specific structure described in the access method's manual page. If openinfo is NULL, each access method will use defaults appropriate for the system and the access method.
The dbopen routine returns a pointer to a DB structure on success and NULL on error. The DB structure is defined in the <db.h> include file, and contains at least these fields:
typedef struct {
DBTYPE type;
int (*close)(const DB *db);
int (*del)(const DB *db, const DBT *key, u_int flags);
int (*fd)(const DB *db);
int (*get)(const DB *db, DBT *key, DBT *data,
u_int flags);
int (*put)(const DB *db, DBT *key, const DBT *data,
u_int flags);
int (*sync)(const DB *db, u_int flags);
int (*seq)(const DB *db, DBT *key, DBT *data,
u_int flags);
} DB;
The elements of this structure specify the database type and a set of functions required to perform operations on a database of this type. These functions take a pointer to a structure as returned by dbopen, and sometimes one or more pointers to key/data structures and a flag value.
Access to all file types is based on key/data pairs. Both keys and data are represented by this data structure:
typedef struct {
void *data;
size_t size;
} DBT;
The elements of the DBT (mnemonic for "data base thang") structure are defined as follows:
Key and data byte strings may reference strings of essentially unlimited length although any two of them must fit into available memory at the same time. It should be noted that the access methods provide no guarantees about byte string alignment.
The dbopen routine may fail and set errno for any of the errors specified for the library routines open(2) and malloc(3) or the following:
The close routines may fail and set errno for any of the errors specified for the library routines close(2), read(2), write(2), free(3), or fsync(2).
The del, get, put, and seq routines may fail and set errno for any of the errors specified for the library routines read(2), write(2), free(3), or malloc(3).
The fd routines will fail and set errno to ENOENT for any of the errors specified in memory databases.
The sync routines may fail and set errno for any of the errors specified for the library routine fsync(2).
None of the access methods provides any form of concurrent access, locking, or transactions.
#include <db.h>
The routine dbopen is the library interface to database files. One of the supported file formats is btree files. For a general description of the database access methods, see dbopen(3); this describes only the btree-specific information.
The btree data structure is a sorted, balanced tree structure storing associated key/data pairs.
The btree access method specific data structure provided to dbopen is defined in the <db.h> include file as follows:
typedef struct {
u_long flags;
u_int cachesize;
int maxkeypage;
int minkeypage;
u_int psize;
int (*compare)(const DBT *key1, const DBT *key2);
size_t (*prefix)(const DBT *key1, const DBT *key2);
int lorder;
} BTREEINFO;
The elements of this structure are as follows:
If the file already exists (and the O_TRUNC flag is not specified), the values specified for the parameters flags, lorder, and psize are ignored in favor of the values used when the tree was created.
Forward sequential scans of a tree are from the least key to the greatest.
Space freed up by deleting key/data pairs from the tree is never reclaimed, although it is normally made available for reuse. This means that the btree storage structure is grow-only. The only solutions are to avoid excessive deletions, or to create a fresh tree periodically from a scan of an existing one.
Searches, insertions, and deletions in a btree will all complete in O (ln N) where N is the average fill factor. Often, inserting ordered data into a btree results in a low fill factor. This implementation has been modified to make ordered insertion the best case, resulting in a much better-than-normal page fill factor.
The btree access method routines may fail and set errno for any of the errors specified for the library routine dbopen(3).
#include <db.h>
The routine dbopen is the library interface to database files. One of the supported file formats is hash files. For a general description of the database access methods, see dbopen(3); this describes only the hash specific information.
The hash data structure is an extensible, dynamic hashing scheme.
The access method specific data structure provided to dbopen is defined in the <db.h> include file as follows:
typedef struct {
u_int bsize;
u_int ffactor;
u_int nelem;
u_int cachesize;
u_int32_t (*hash)(const void *, size_t);
int lorder;
} HASHINFO;
The elements of this structure are as follows:
If the file already exists (and the O_TRUNC flag is not specified), the values specified for the parameters bsize, ffactor, lorder, and nelem are ignored and the values specified when the tree was created are used.
If a hash function is specified, hash_open attempts to determine if the hash function specified is the same as the one with which the database was created, and will fail if it is not.
Backwardly compatible interfaces to the routines described in dbm(3) and ndbm(3) are provided; however, these interfaces are not compatible with previous file formats.
The hash access method routines may fail and set errno for any of the errors specified for the library routine dbopen(3).
The example below shows a simple query tool written in the C programming language. Note that it works only for btree tables and that views are not supported.
#include <db.h>
main(int argc,char *argv[])
{
DB *db;
DBT data,key;
int flag,len;
char *pattern;
if (argc != 3)
{
printf("usage: %s database pattern\n",argv[0]);
exit(1);
}
if (!(db = dbopen(argv[1],O_RDONLY,0644,DB_BTREE,NULL)))
{
fprintf(stderr,"Could not open \
\"%s\",%s\n",argv[1],
strerror(errno));
exit(2);
}
pattern = argv[2];
len = strlen(pattern);
key.data = (void *)pattern;
key.size = len;
for(flag = R_FIRST;
db->seq(db,&key,&data,flag) == 0 &&
strncmp(key.data,pattern,len) == 0; flag = R_NEXT)
{
printf("key: %s\n",key.data);
printf("data: %s\n",data.data);
}
db->close(db);
exit (0);
}
To compile and link you can use the following Makefile:
SDK=/export/home/tom/snavigator/sdk CFLAGS= -I$(SDK)/include LIB= -L$(SDK)/lib -lpafdb dbqry: dbqry.c $(CC) -o $@ $< $(LIB)
Source-Navigator stores information about source files in project (database) tables to assure high performance with flexible query possibilities.
With the exception of the project file (that is itself also a hash database table), every table normally relies on the SNDB4 sub-directory of the project and can be accessed like any other database table. The following example shows what the table structure of a project database looks like on a UNIX system. It was produced using the shell command ls -l SNDB4.
-rw-r--r-- 1 user sys 16384 Aug 12 12:19 cpl.1 -rw-r--r-- 1 user sys 16384 Aug 12 12:34 cpl.2 -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.by -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.cl -rw-r--r-- 1 user sys 16384 Aug 12 12:19 cpl.f -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.fil -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.fu -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.gv -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.iv -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.md -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.mi -rw-r--r-- 1 user sys 8192 Aug 12 12:19 cpl.to
In the following table, the symbol ? represents the sn_sep separator character. See the scripts under Cross-Reference Tables for more information on this variable. Additionally, all of the following keys must be on one line.
The hash # character in class names means that the symbol does not belong to any classes, and semicolon (;) separates the key and data parts. Positions consist of line and column numbers separated by a comma (,).
The Tcl script below opens a table for a fictitious Source-Navigator project named pure.
#!/bin/sh
# Replace $HOME/snavigator with the Source-Navigator
# installation directory! \
exec $HOME/snavigator/bin/hyper "$0" "$@"
#
# Don't forget the backslash before exec!
#
set db_functions [dbopen nav_func SNDB4/pure.fu RDONLY \
0644 btree cachesize=200000]
# Output the list of matches with newline characters after
# each.
puts [join [$db_functions seq] \n]
This shell script produces the following result:
{chk 000011.012 chk.c} {17.1 0x8 {void} {int} {size} {}}
{fnc1 000019.012 chk.c} {33.1 0x8 {void} {int,int,char *}
{i,size,str} {}}
{keys 000026.005 keybind.tcl} {28.1 0x0 {} {} {k} {}}
{main 000035.000 chk.c} {38.1 0x0 {int} {} {} {}}
Each record contains two Tcl lists: the first is the key part, the second is the data part. If -key, -data or -columns is used, the key and the data parts are always retrieved in separate Tcl lists.
If you use the -data switch in the fetch command (e.g. $db_functions seq -data ) in the example script above, only the key is fetched and the result is the following:
chk 000011.012 chk.c fnc1 000019.012 chk.c keys 000026.005 keybind.tcl main 000035.000 chk.c
To restrict the result to functions whose names begin with main, use the following command:
$db_functions seq -data "main"
To fetch only the functions with the name main, you should add a blank to the key value:
$db_functions seq -data "main$sn_sep"
The -columns switch can be used to change the order of fields. The query below retrieves the name of the files, then the name of the functions and their positions:
$db_functions seq -data -columns [list 2 0 1]
chk.c chk 000011.012 chk.c fnc1 000019.012 keybind.tcl keys 000026.005 chk.c main 000035.000
As described on Fetch Methods, the Tcl list following -columns contains sub-lists. The first element of a sub-list identifies (offset number beginning from 0) which field should be retrieved, and the second element is an optional format that controls formatting. In the example below, the "" appends a blank after every retrieved field. Sometimes it is useful to use \t (tab) instead of blanks. In Source-Navigator, types are often shown in parentheses.
For example, to obtain a listing of every function, indicated as (fu), the following command
$db_functions seq -data -columns [list {2 "(fu) "} 0 1]
chk.c(fu) chk 000011.012 chk.c(fu) fnc1 000019.012 keybind.tcl(fu) keys 000026.005 chk.c(fu) main 000035.000
The format characters :, <, >, and = can be used to make comparisons of database table field contents. When a condition is not true, the record is not retrieved.
For the purposes of this example, the source file where the following C++ class TEST is defined will be called test.cc .
class TEST {
private:
int inm()
{
return 0;
}
outside(int x,int y);
public:
static void copy(){}
protected:
int var;
};
TEST::outside(int x,int y)
{
}
The Tcl script below queries the project for all of the public methods of classes that have been defined in test.cc. The value 4 used in the example maps to the constant PAF_PUBLIC from sn.h.
#!/bin/sh # Replace $HOME/snavigator with the Source-Navigator # installation directory! \ exec $HOME/snavigator/bin/hyper "$0" "$@" # # Don't forget the backslash before exec! # set db_prefix .sn/doc.md set db [dbopen methods_db $db_prefix RDONLY 0444 btree] set res [$db seq -col [list 0 1 3 2 "5 :0:4"] -end "test.cc"] # 4 -> 1 for private methods, 4 -> 5 for public and private methods puts [join $res "\n"]
The script produces this output:
TEST copy test.cc 000009.014 0x200c
To query the private methods, change the value 4 to 1 (the value of PAF_PUBLIC).
This modified script produces this output:
TEST inm test.cc 000003.006 0x2001 TEST outside test.cc 000007.002 0x1
To query the public and private methods, use the value 5. This is the bitwise OR of the values for PAF_PRIVATE and PAF_PUBLIC.
To query all static (SN_STATIC) methods defined in test.cc, change the script as follows:
set res [$db seq -col [list 0 1 3 2 "5 :8:7"] -end "test.cc"]
To query every method between lines 7-9 in test.cc, make the following query:
set res [$db seq -col [list 0 1 3 \ "2 <10" "2 >6"] -end "test.cc"]
The Source-Navigator installation contains a number of larger examples for useful tools that can be quickly realized using the database API. They are located in .../share/sdk/api/tcl/database/examples.
Source-Navigator can assist in a wide variety of software engineering and re-engineering tasks and these examples tend to address the common scenario of bringing under control inherited bodies of source code that may be poorly written and poorly understood.
These examples are all written in the Tcl programming language. Some examples utilize the Tk toolkit. None of the examples require that Source-Navigator be running in order to use them. They work on the database directly using the database API provided by the hyper interpreter that comes with Source-Navigator.
At the top of each script is a path to the interpreter that may need to be edited to locate hyper on your system.
Most of the examples require at least two command line arguments: the path to the Source-Navigator project directory and the name of the project you're interested in. More details can be found in the comment block at the top of each script file, and each script is quite heavily documented.
The example scripts are described below.
This tool reports on redundant header files. By reducing #include complexity in a source file, compilation time can be reduced. This tool locates simple duplication, whereby foo.c may include bar.h (e.g. #include "bar.h") and then bar.h again later. By optionally specifying a -transitive command line argument to the script, a more thorough search through the header file graph is performed, such that includes of stdio.h may be detected as unnecessary if another included header file includes it on your behalf.
This tool locates multiple inheritance "diamonds" in the class hierarchy of a project written in an object-oriented language like C++. In his book, Effective C++ 4, Scott Myers points out the dangers associated with class hierarchies in which two classes derived from the same superclass are inherited by a fourth derived-most class. Diamonds are universally considered to be poor C++ programming practice and this tool can locate them in a Source-Navigator project.
This tool plots the caller/callee frequencies for all functions and methods in a project. Functions appearing to have called many functions or that are called by many functions may be ones requiring coverage testing, additional documentation, optimization, etc.
Each function is represented as a point on a graph. Clicking on a point opens a list box showing the name of the function and the caller/callee statistics.
This tool shows the names of all functions/methods in a project that modify a particular global variable.
This tool identifies global variables in projects which are accessed as read-only objects. These variables are therefore candidates for becoming constants.
This tool locates class method definitions that are surplus to a class (i.e. for which there is no method implementation). This tool is not always accurate as it will also suggest that methods that are defined inline are not implemented when they actually are.
This tool determines where unused global variables exist in a project.
1. Welch, Brent B. 1997. Practical Programming in Tcl and Tk. 2nd ed. ISBN 0-13-616830-2. Return to text
2. Ousterhout, John K. 1994. Tcl and the Tk Toolkit. ISBN 0-201-63337-X. Return to text
3. Kernighan, Brian W., and Dennis M. Ritchie. 1988. The C Programming Language. 2nd ed. ISBN 0-13-110362-8. Return to text
4. Meyers, Scott. 1997. Effective C++: 50 Specific Ways to Improve Your Programs and Designs. 2nd ed. ISBN 0-20-192488-9. Return to text