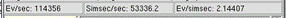
Figure: Performance bar in OMNeT++ showing P, R and E
OMNeT++ supports parallel execution of large simulations. This section provides a brief picture of the problems and methods of parallel discrete event simulation (PDES). Interested readers are strongly encouraged to look into the literature.
For parallel execution, the model is to be partitioned into several LPs (logical processes) that will be simulated independently on different hosts or processors. Each LP will have its own local Future Event Set, and thus will maintain its own local simulation time. The main issue with parallel simulations is keeping LPs synchronized in order to avoid violating the causality of events. Without synchronization, a message sent by one LP could arrive in another LP when the simulation time in the receiving LP has already passed the timestamp (arrival time) of the message. This would break causality of events in the receiving LP.
There are two broad categories of parallel simulation algorithms that differ in the way they handle causality problems outlined above:
OMNeT++ currently supports conservative synchronization via the classic Chandy-Misra-Bryant (or null message) algorithm [chandymisra79]. To assess how efficiently a simulation can be parallelized with this algorithm, we'll need the following variables:
In large simulation models, P, E and R usually stay relatively constant (that is, display little fluctuations in time). They are also intuitive and easy to measure. The OMNeT++ displays these values on the GUI while the simulation is running, see Figure below. Cmdenv can also be configured to display these values.
After having approximate values of P, E, L and τ, calculate the λ coupling factor as the ratio of LE and τ P:
λ = (LE) / (τ P)
Without going into the details: if the resulting λ value is at minimum larger than one, but rather in the range 10..100, there is a good chance that the simulation will perform well when run in parallel. With λ < 1, poor performance is guaranteed. For details see the paper [ParsimCrit03].
This chapter presents the parallel simulation architecture of OMNeT++. The design allows simulation models to be run in parallel without code modification -- it only requires configuration. The implementation relies on the approach of placeholder modules and proxy gates to instantiate the model on different LPs -- the placeholder approach allows simulation techniques such as topology discovery and direct message sending to work unmodified with PDES. The architecture is modular and extensible, so it can serve as a framework for research on parallel simulation.
The OMNeT++ design places a big emphasis on separation of models from experiments. The main rationale is that usually a large number of simulation experiments need to be done on a single model before a conclusion can be drawn about the real system. Experiments tend to be ad-hoc and change much faster than simulation models; thus it is a natural requirement to be able to carry out experiments without disturbing the simulation model itself.
Following the above principle, OMNeT++ allows simulation models to be executed in parallel without modification. No special instrumentation of the source code or the topology description is needed, as partitioning and other PDES configuration is entirely described in the configuration files.
OMNeT++ supports the Null Message Algorithm with static topologies, using link delays as lookahead. The laziness of null message sending can be tuned. Also supported is the Ideal Simulation Protocol (ISP) introduced by Bagrodia in 2000 [bagrodia00]. ISP is a powerful research vehicle to measure the efficiency of PDES algorithms, both optimistic and conservative; more precisely, it helps determine the maximum speedup achievable by any PDES algorithm for a particular model and simulation environment. In OMNeT++, ISP can be used for benchmarking the performance of the Null Message Algorithm. Additionally, models can be executed without any synchronization, which can be useful for educational purposes (to demonstrate the need for synchronization) or for simple testing.
For the communication between LPs (logical processes), OMNeT++ primarily uses MPI, the Message Passing Interface standard [mpiforum94]. An alternative communication mechanism is based on named pipes, for use on shared memory multiprocessors without the need to install MPI. Additionally, a file system based communication mechanism is also available. It communicates via text files created in a shared directory, and can be useful for educational purposes (to analyse or demonstrate messaging in PDES algorithms) or to debug PDES algorithms. Implementation of a shared memory-based communication mechanism is also planned for the future, to fully exploit the power of multiprocessors without the overhead of and the need to install MPI.
Nearly every model can be run in parallel. The constraints are the following:
PDES support in OMNeT++ follows a modular and extensible architecture. New communication mechanisms can be added by implementing a compact API (expressed as a C++ class) and registering the implementation -- after that, the new communications mechanism can be selected for use in the configuration.
New PDES synchronization algorithms can be added in a similar way. PDES algorithms are also represented by C++ classes that have to implement a very small API to integrate with the simulation kernel. Setting up the model on various LPs as well as relaying model messages across LPs is already taken care of and not something the implementation of the synchronization algorithm needs to worry about (although it can intervene if needed, because the necessary hooks are provided).
The implementation of the Null Message Algorithm is also modular in itself in that the lookahead discovery can be plugged in via a defined API. Currently implemented lookahead discovery uses link delays, but it is possible to implement more sophisticated approaches and select them in the configuration.
We will use the Parallel CQN example simulation for demonstrating the PDES capabilities of OMNeT++. The model consists of N tandem queues where each tandem consists of a switch and k single-server queues with exponential service times (Figure below). The last queues are looped back to their switches. Each switch randomly chooses the first queue of one of the tandems as destination, using uniform distribution. The queues and switches are connected with links that have nonzero propagation delays. Our OMNeT++ model for CQN wraps tandems into compound modules.

To run the model in parallel, we assign tandems to different LPs (Figure below). Lookahead is provided by delays on the marked links.

To run the CQN model in parallel, we have to configure it for parallel execution. In OMNeT++, the configuration is in the omnetpp.ini file. For configuration, first we have to specify partitioning, that is, assign modules to processors. This is done by the following lines:
[General] *.tandemQueue[0]**.partition-id = 0 *.tandemQueue[1]**.partition-id = 1 *.tandemQueue[2]**.partition-id = 2
The numbers after the equal sign identify the LP.
Then we have to select the communication library and the parallel simulation algorithm, and enable parallel simulation:
[General] parallel-simulation = true parsim-communications-class = "cMPICommunications" parsim-synchronization-class = "cNullMessageProtocol"
When the parallel simulation is run, LPs are represented by multiple running instances of the same program. When using LAM-MPI [lammpi], the mpirun program (part of LAM-MPI) is used to launch the program on the desired processors. When named pipes or file communications is selected, the opp_prun OMNeT++ utility can be used to start the processes. Alternatively, one can run the processes by hand (the -p flag tells OMNeT++ the index of the given LP and the total number of LPs):
./cqn -p0,3 & ./cqn -p1,3 & ./cqn -p2,3 &
For PDES, one will usually want to select the command-line user interface, and redirect the output to files. (OMNeT++ provides the necessary configuration options.)
The graphical user interface of OMNeT++ can also be used (as evidenced by Figure below), independently of the selected communication mechanism. The GUI interface can be useful for educational or demonstration purposes. OMNeT++ displays debugging output about the Null Message Algorithm, EITs and EOTs can be inspected, etc.
When setting up a model partitioned to several LPs, OMNeT++ uses placeholder modules and proxy gates. In the local LP, placeholders represent sibling submodules that are instantiated on other LPs. With placeholder modules, every module has all of its siblings present in the local LP -- either as placeholder or as the “real thing”. Proxy gates take care of forwarding messages to the LP where the module is instantiated (see Figure below).
The main advantage of using placeholders is that algorithms such as topology discovery embedded in the model can be used with PDES unmodified. Also, modules can use direct message sending to any sibling module, including placeholders. This is so because the destination of direct message sending is an input gate of the destination module -- if the destination module is a placeholder, the input gate will be a proxy gate which transparently forwards the messages to the LP where the “real” module was instantiated. A limitation is that the destination of direct message sending cannot be a submodule of a sibling (which is probably a bad practice anyway, as it violates encapsulation), simply because placeholders are empty and so its submodules are not present in the local LP.
Instantiation of compound modules is slightly more complicated. Since submodules can be on different LPs, the compound module may not be “fully present” on any given LP, and it may have to be present on several LPs (wherever it has submodules instantiated). Thus, compound modules are instantiated wherever they have at least one submodule instantiated, and are represented by placeholders everywhere else (Figure below).


Parallel simulation configuration is the [General] section of omnetpp.ini.
The parallel distributed simulation feature can be turned on with the parallel-simulation boolean option.
The parsim-communications-class selects the class that implements communication between partitions. The class must implement the cParsimCommunications interface.
The parsim-synchronization-class selects the parallel simulation algorithm. The class must implement the cParsimSynchronizer interface.
The following two options configure the Null Message Algorithm, so they are only effective if cNullMessageProtocol has been selected as synchronization class:
The parsim-debug boolean option enables/disables printing log messages about the parallel simulation algorithm. It is turned on by default, but for production runs we recommend turning it off.
Other configuration options configure MPI buffer sizes and other details; see options that begin with parsim- in Appendix [26].
When you are using cross-mounted home directories (the simulation's directory is on a disk mounted on all nodes of the cluster), a useful configuration setting is
[General] fname-append-host = true
It will cause the host names to be appended to the names of all output vector files, so that partitions don't overwrite each other's output files. (See section [11.21.3.3])
The design of PDES support in OMNeT++ follows a layered approach, with a modular and extensible architecture. The overall architecture is depicted in Figure below.

The parallel simulation subsytem is an optional component itself, which can be removed from the simulation kernel if not needed. It consists of three layers, from the bottom up: Communications Layer, Partitioning Layer and Synchronization Layer.
The purpose of the Communications Layer is to provide elementary messaging services between partitions for the upper layer. The services include send, blocking receive, nonblocking receive and broadcast. The send/receive operations work with buffers, which encapsulate packing and unpacking operations for primitive C++ types. The message class and other classes in the simulation library can pack and unpack themselves into such buffers. The Communications layer API is defined in the cParsimCommunications interface (abstract class); specific implementations like the MPI one (cMPICommunications) subclass from this, and encapsulate MPI send/receive calls. The matching buffer class cMPICommBuffer encapsulates MPI pack/unpack operations.
The Partitioning Layer is responsible for instantiating modules on different LPs according to the partitioning specified in the configuration, for configuring proxy gates. During the simulation, this layer also ensures that cross-partition simulation messages reach their destinations. It intercepts messages that arrive at proxy gates and transmits them to the destination LP using the services of the Communications Layer. The receiving LP unpacks the message and injects it at the gate the proxy gate points at. The implementation basically encapsulates the cParsimSegment, cPlaceholderModule, cProxyGate classes.
The Synchronization Layer encapsulates the parallel simulation algorithm. Parallel simulation algorithms are also represented by classes, subclassed from the cParsimSynchronizer abstract class. The parallel simulation algorithm is invoked on the following hooks: event scheduling, processing model messages outgoing from the LP, and messages (model messages or internal messages) arriving from other LPs. The first hook, event scheduling, is a function invoked by the simulation kernel to determine the next simulation event; it also has full access to the future event set (FES) and can add/remove events for its own use. Conservative parallel simulation algorithms will use this hook to block the simulation if the next event is unsafe, e.g. the null message algorithm implementation (cNullMessageProtocol) blocks the simulation if an EIT has been reached until a null message arrives (see [bagrodia00] for terminology); also it uses this hook to periodically send null messages. The second hook is invoked when a model message is sent to another LP; the null message algorithm uses this hook to piggyback null messages on outgoing model messages. The third hook is invoked when any message arrives from other LPs, and it allows the parallel simulation algorithm to process its own internal messages from other partitions; the null message algorithm processes incoming null messages here.
The Null Message Protocol implementation itself is modular; it employs a separate, configurable lookahead discovery object. Currently only link delay based lookahead discovery has been implemented, but it is possible to implement more sophisticated types.
The Ideal Simulation Protocol (ISP; see [bagrodia00]) implementation consists of two parallel simulation protocol implementations: the first one is based on the null message algorithm and additionally records the external events (events received from other LPs) to a trace file; the second one executes the simulation using the trace file to find out which events are safe and which are not.
Note that although we implemented a conservative protocol,
the provided API itself would allow implementing optimistic
protocols, too. The parallel simulation algorithm has
access to the executing simulation model, so it could perform
saving/restoring model state if model objects support this
We also expect that because of the modularity, extensibility and clean internal architecture of the parallel simulation subsystem, the OMNeT++ framework has the potential to become a preferred platform for PDES research.